DINOv2 の実力:VRAM使用量と処理速度をGTX1080で検証
はじめに#
今回、画像処理界隈で話題だったDino v2の精度について検討していきます。 Dino V2 とはMeta社が開発した、特徴量抽出のモデルです。
昔から画像処理の世界では特定の画像を切り出したり、タグ付けしたり、分類、3D化するなどの技術が研究されています。DINOv2は「物体の意味的な特徴」を抽出することを目的としたものですが、特徴量抽出の一種と見ることが出来ます。
そのため、セグメンテーション、前景切り出し、震度マップ作成といわれる技術に対し、検出や認識の精度が上げる技術がDINOv2といえます。例えば既存のライブラリの入力にDINOv2から出てきた特徴量を使うだけで精度があがるのです。
DinoV2は2023年4月に発表されており、2025年3月でほぼ2年経ちますが、いまだにトップクラスの技術となっています。 技術内容については別のときに機会があれば(多分ない)紹介しますが、今回は技術内容ではなく、実際に画像を入れてみてどうなるのか、どういう精度なのか、速度、メモリはどの程度なのかということを実例ベースで検証しようかと思います。
今回検証に使ったコードはgithubにあげてあります。
はじめ#
次の4枚の画像を入力します。(画像は著作権フリーではありませんので、保存等はせず閲覧にしてください)

DINOv2では、次の4つのモデルが用意されています。
ViT-s/14 : 384次元
ViT-b/14 : 768次元
ViT-l/14 : 1024次元
ViT-g/14 : 1536次元
それぞれは、画像を入れると 384次元、768次元、1024次元、1536次元の特徴量を出力します。 どれくらいのVRAMが必要なのか調べてみたところ一番小さいViT-s(384次元)で300MB程度, ViT-bで600MB程度, ViT-lで1.5GB程度, ViT-gで5GB程度になっていました。(最後にまとめてあります)
早速DINOv2を適用して、PCA分析すると、それぞれがどのような結果になるのか表示します。
主成分分析をしてみる#
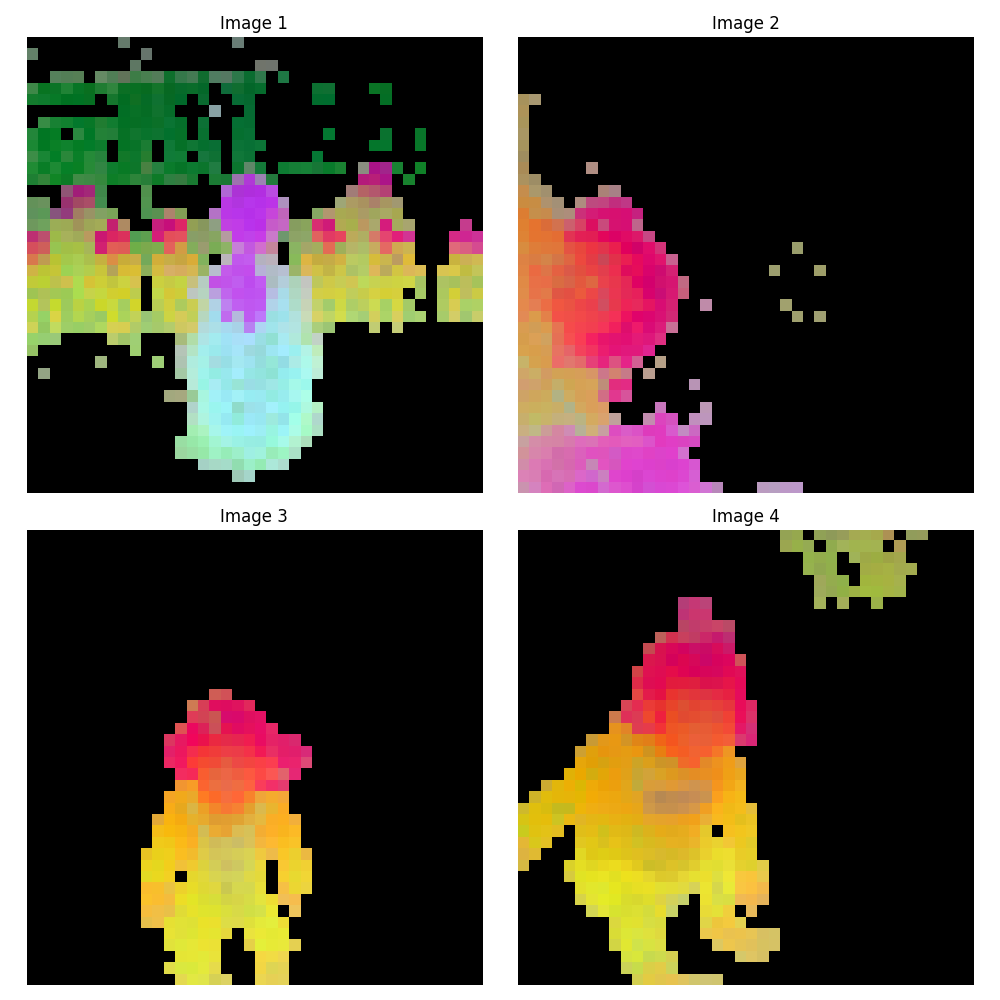
ViT-s/14 (384次元)#
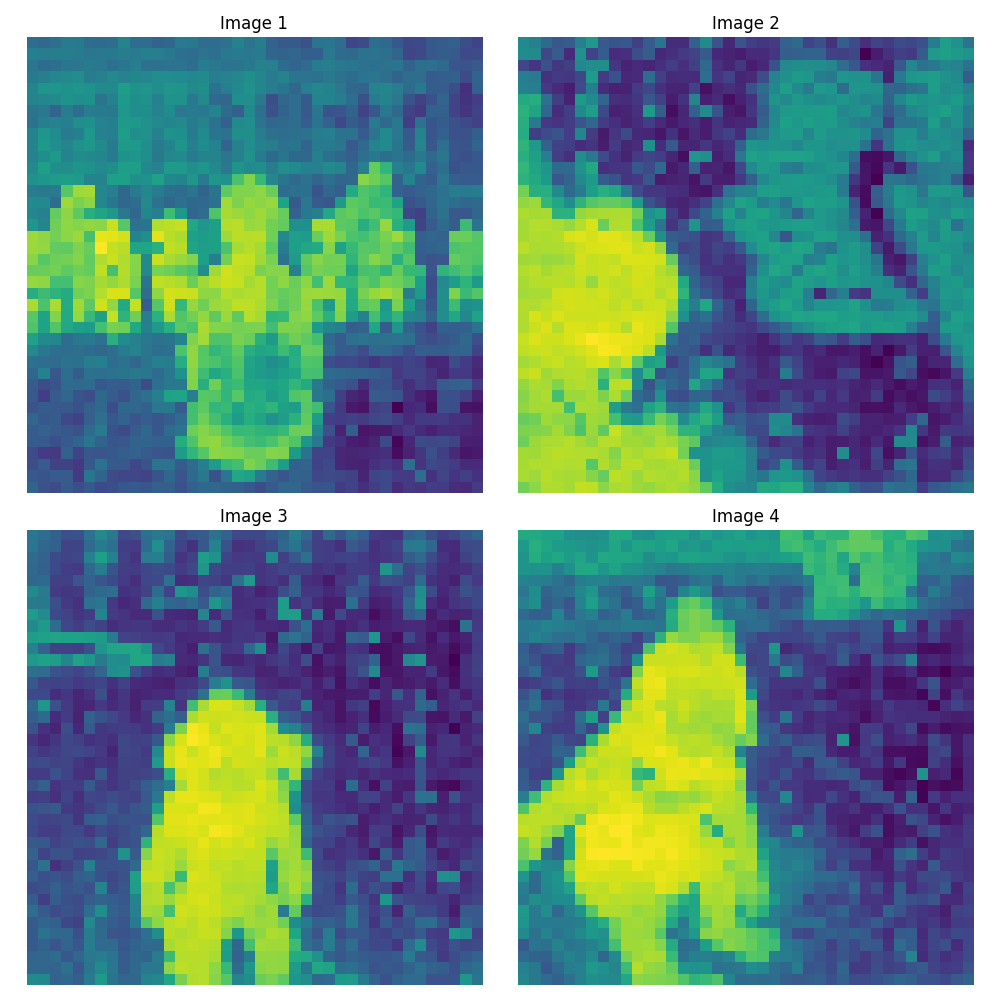
ViT-b/14 (768次元)#
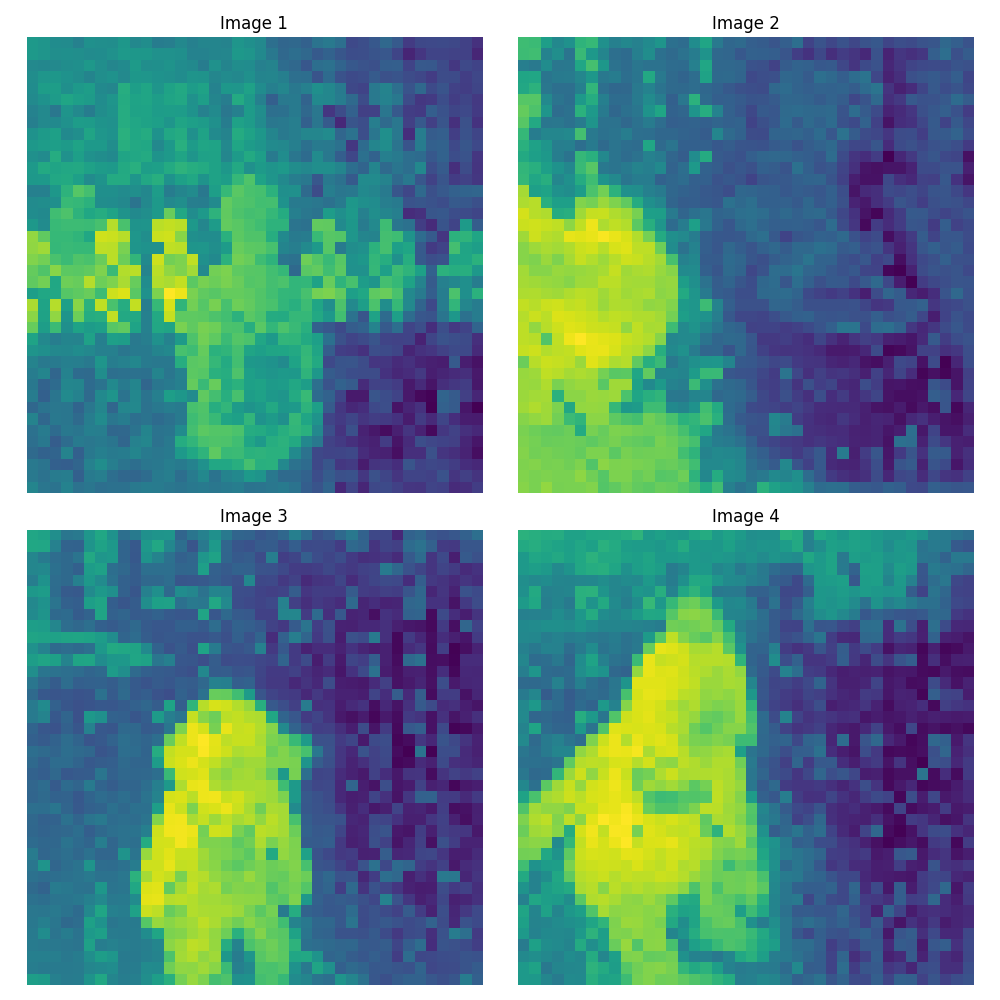
ViT-l/14 (1024次元)#
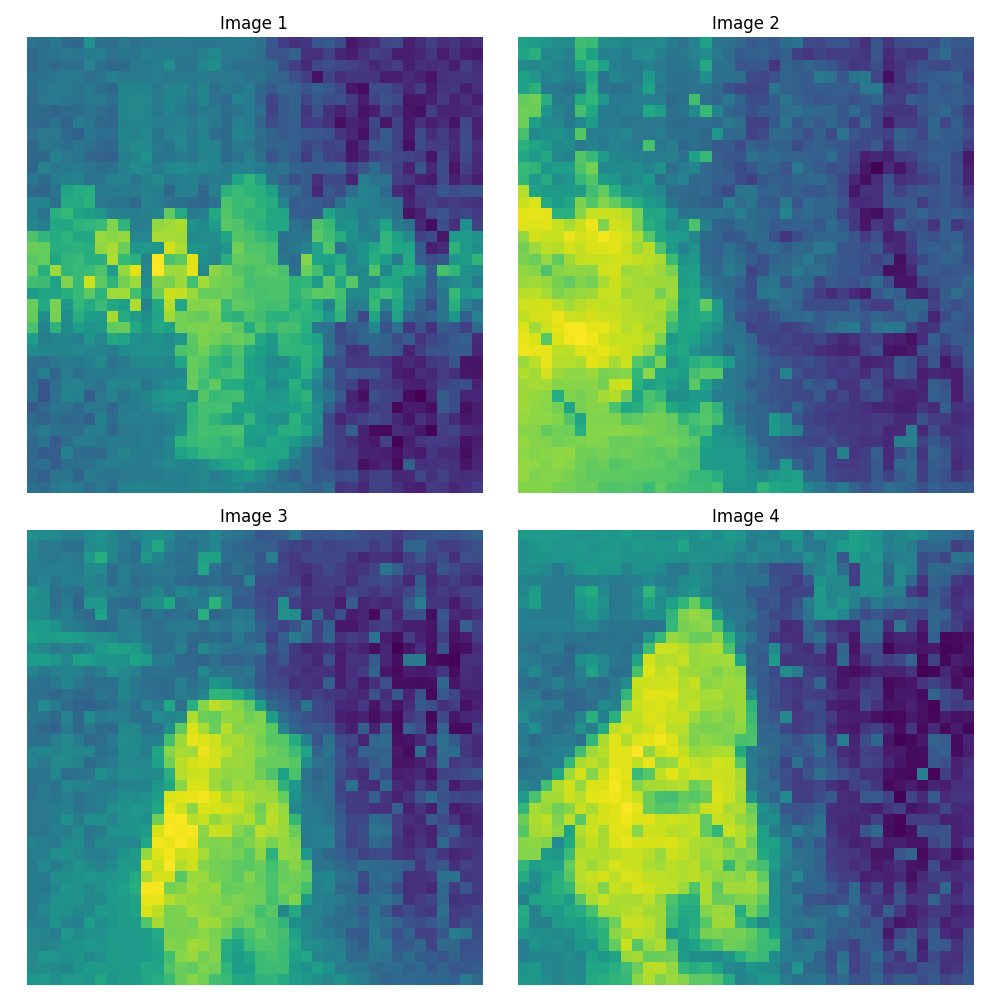
ViT-g/14 (1536次元)#
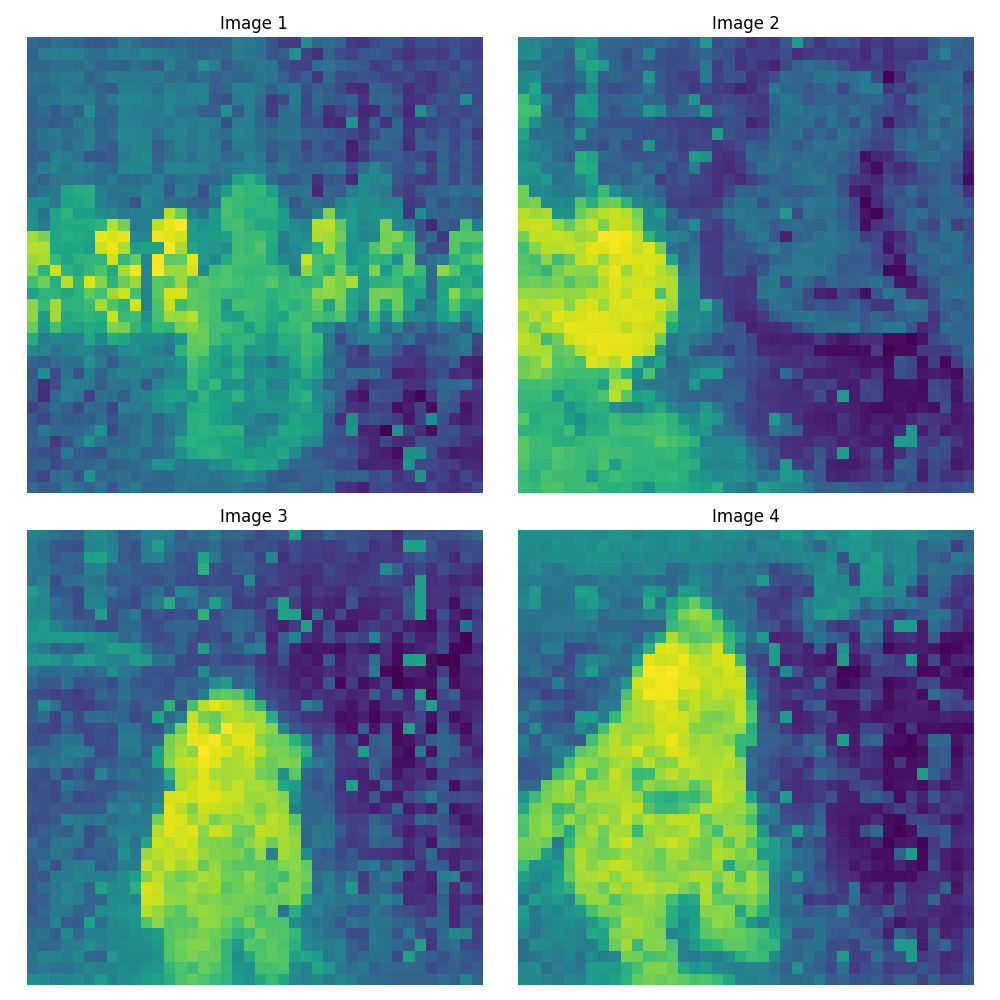
画像を見ると解ると思いますが、画像を見て人が注目するようなところが反応している事に気づきます。こうした技術を最近ではattention技術といいますが、近年のAIの技術の主要な技術です。 attentionについては弊社ブログで簡単に説明しています。
さて、画像を見ていってどういう特徴があるのか確認していきます。Image1には後ろ向きの女性が写っていますが、モデルの精度が上がるに連れAttentionが低くなっていっています。後ろ向きの女性の重要度が低いと判断されているとわかります。
Image2ですが、横向きの子供の顔も問題なく反応しています。精度が上がるごとに、子供の顔への反応も強くなっています。
Image3は女の子に対しAttentionがうまく出来ていることが確認できます。精度が上がるごとに顔付近が一番反応してくるように変わっていっています。
Image4では、背景に子どもたちの足があります。1番小さいモデルではその部分に反応していましたが、上がるに連れて価値のない(Attentionが低い)ものとして扱われてきています。
PCAに基づく適応的な領域分割と特徴抽出:#
続いて前段のPCAで反応しているところだけを切り抜いて、そこに対してPCAを再度行い、切り抜いた特徴量をMappingしていきたいと思います。 詳しいコードはgithubに上げますのでご参照下さい
ViT-s/14 (384次元)#
ViT-b/14 (768次元)#
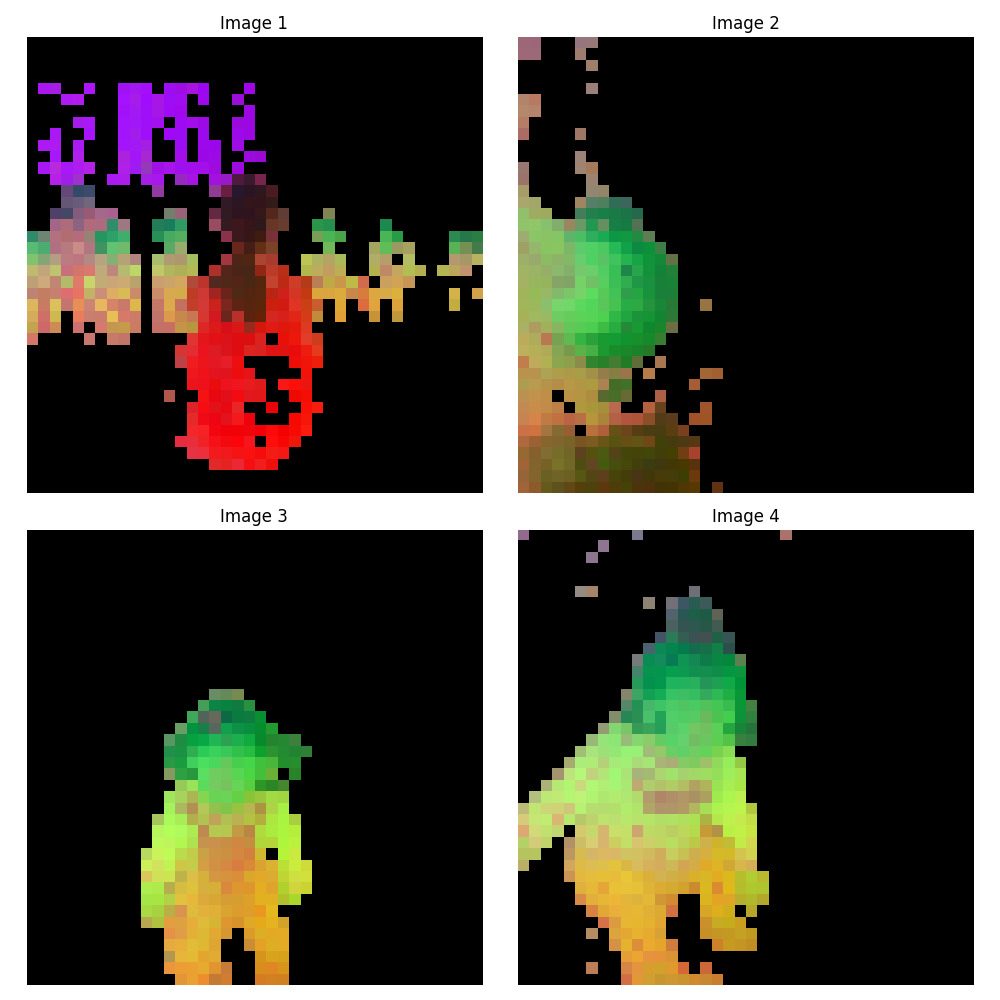
ViT-l/14 (1024次元)#
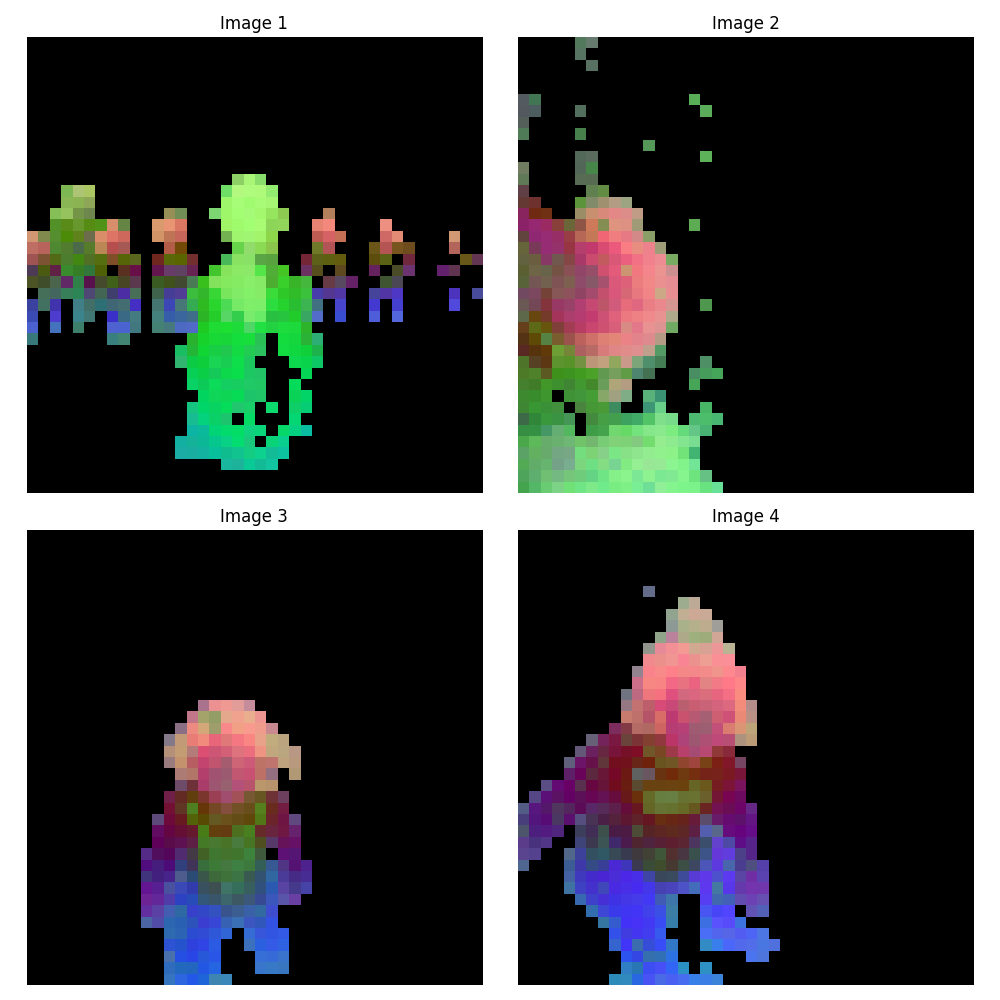
ViT-g/14 (1536次元)#
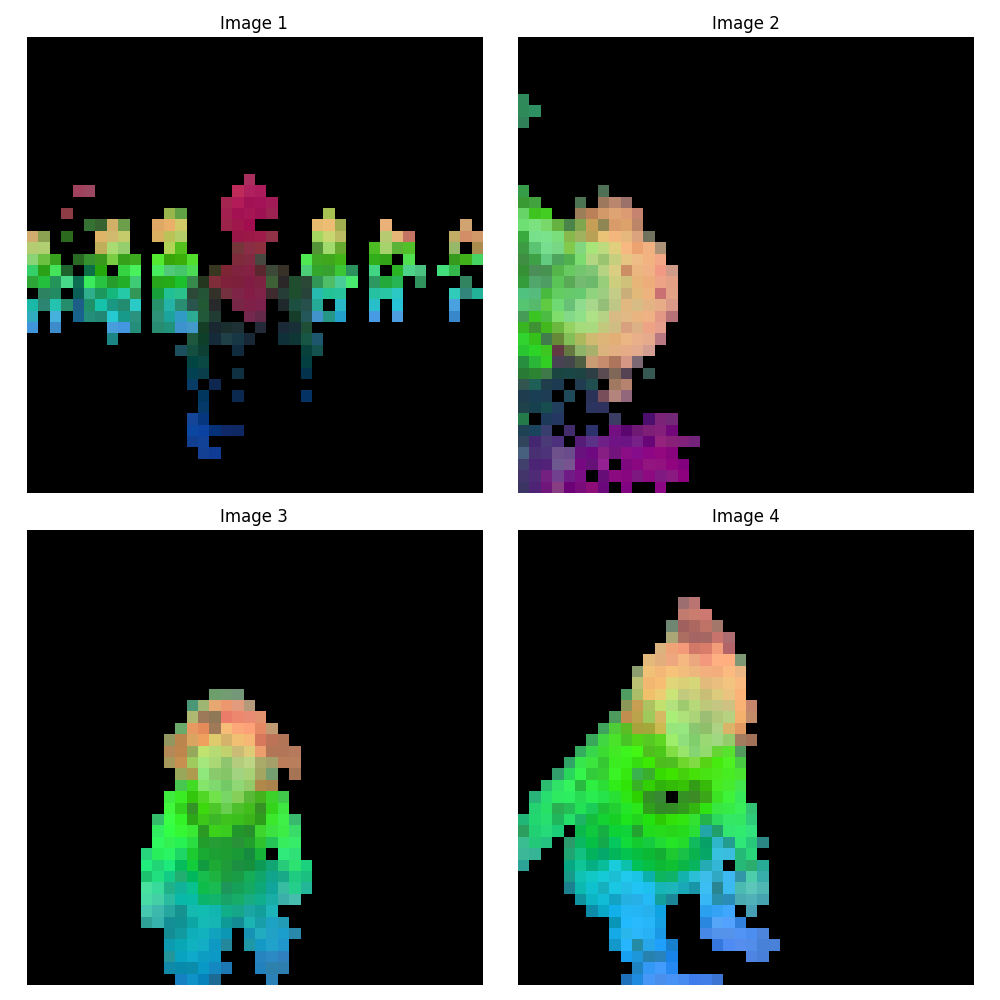
切り出した特徴量を可視化すると、画像中のパーツごとに異なる色で表現されており、セマンティックな情報が特徴量空間に反映されていることが確認できます。 一番小さいViT-s/14モデルでも意外と反応しているな、と感じます。
処理時間ですがViT-g/14は明らかに重く、gtx1080(8gb RAM)で一枚あたり2秒ほど処理に時間がかかっています。 一方でVit-s 0.05秒, Vit-bで 0.1秒, Vit-l 0.35秒です。まとめると次のようになります。
| モデル | 次元 | VRAM (目安) | 処理時間 (目安, GTX1080) | 精度 (主観) |
|---|---|---|---|---|
| ViT-s/14 | 384 | 300MB | 0.05秒 | 中の下 |
| ViT-b/14 | 768 | 600MB | 0.1秒 | 中 |
| ViT-l/14 | 1024 | 1.5GB | 0.35秒 | 上 |
| ViT-g/14 | 1536 | 5GB | 2秒 | 上の中 |
なお、Intel core i5のCPU処理だと、ViT-b/14の出力に20秒かかっていました。GPUがないときつそうです。
まとめ#
今回の検証では、Meta社が開発した特徴量抽出モデルDINOv2を用いて、画像に対するPCA分析と適応的な領域分割・特徴抽出を行いました。
DINOv2には、ViT-s/14からViT-g/14まで、4つのモデルサイズが存在し、それぞれ特徴量の次元数とVRAMの使用量が異なります。
PCA分析の結果、DINOv2は画像中のAttentionすべき領域を捉え、モデルの精度が上がるにつれて、より重要な領域にAttentionが集中する傾向が見られました。特に、人物の顔や、前景の物体など、画像の意味的な情報を持つ領域に高いAttentionが与えられていることが確認できました。
また、PCAに基づいて適応的な領域分割と特徴抽出を行った結果、切り出された特徴量を可視化すると、画像中のパーツごとに異なる色で表現され、セマンティックな情報が特徴量空間に反映されていることが確認できました。これは、DINOv2が単なる画像の特徴だけでなく、画像の意味的な構造も学習していることを示唆しています。
処理時間については、モデルサイズが大きくなるにつれて増加する傾向にあり、ViT-g/14ではGTX1080(8GB RAM)で1枚あたり2秒程度の処理時間を要しました。一番重いモデルは2秒ほどかかる、またVRAMも5GB必要ですので、一般家庭用PCではリアルタイム処理は現在のところ難しそうです。また、768次元を出力するのにi5-2500k CPUで20秒程かかりました。ここの点からも、GPUは必須な感じがします。

画像処理エンジニア。組み込みソフト出身。 株式会社モルフォにてR&D部門、主に機械学習業務に携わり、顔認識&顔検出のアルゴリズム開発に従事。国内特許数件、国際特許1件。 モルフォ社退社後、株式会社Dynaptico創業(CEO)。アメリカ人、スウェーデン人と3名とフードデリバリーサイトmaishoku.comを立ち上げる。社長業の他、開発業務においてバックグラウンド関連全般(Djangoを用いいたバックエンドサーバ&APIサーバーの作成、 リバースプロキシなどの負荷分散サーバ関連、OCRプログラムの作成、CISCOルータの管理, 、seleniumを用いたテストサーバーの構築、Androidアプリの開発等々)に携わる。 2019年DynapticoのCEOを辞職。 2020年2月にComputer Scienceに特化した株式会社OctOpt創業。 OSはUbuntu。Appleが苦手。Swiftのバージョンアップ対応とか死ぬほど嫌い。 Python/C++/C Twitter: @rocky_house シフト自動調整スケジュールサイトをVue.js+graphene djangoで構築. https://www.allshifter.com https://iamfax.com