DifyとXinferenceでローカルRAG環境を構築する
はじめに#
前回の記事では、OllamaとOllama WebUIを使って、ローカル環境でChatGPTライクなチャット環境を構築する方法を紹介しました。
今回はその発展形として、独自のドキュメントやデータを知識源とする、いわゆる「独自ナレッジ対応LLMシステム」を構築する手法である RAG (Retrieval Augmented Generation) に、の構築手法を解説します。
その上で、Dify と Xinference というツールを使って挑戦してみます。
RAGとは#
RAGは Retrieval Augmented Generation の略で、日本語では「検索拡張生成」と訳されます。非常に簡単に言うと、独自のナレッジを持ったシステムを作ることが可能な技法です。(詳細に言えば、LLM(大規模言語モデル)が回答を生成する際に、あらかじめ用意しておいた独自の知識ベースから関連情報を検索(Retrieval)し、その情報を基に回答を生成(Generation)する技術 )
例えば、ゴミ出しの曜日は地域によって変わりますが、横浜市の燃えるゴミの日は水曜日!と、保持しておくことでユーザーの「横浜市の燃えるゴミの日は?」質問に対して的確に答えることが出来ます。
Dify とは#
Dify は、LLMアプリケーションを視覚的に構築、デプロイ、管理できるオープンソースのプラットフォームです。チャットボット、ワークフロー、APIなどをノーコード/ローコードで開発でき、RAGの実装も容易に行えます。
前回のOllama WebUIと比較すると、より多機能で本格的なLLMアプリケーション開発向けのツールと言えるでしょう。
Dify と RAG を組み合わせる:Xinferenceの活用#
RAGシステムを構築する際、検索精度を高めるために重要な役割を果たすのが Embedding と Re-ranking という技術です。(詳しい情報については、前回の記事を参照ください。)
前回はollamaを使ってChatGPTライクなインターフェイスを作りましたが、RAGの構築に必要なRe-rankingがollamaにはありません。そのため今回はRe-rankingモデルも扱えるxinferenceをつかいます。(ollamaは使いません)
Xinferenceを使う理由はre-rankingも自社のGPUで行いたいだけです。Re-rankingを外部のAPI(cohereなど)を使ってDify上で行いたい場合は、ollamaを使っても全く構いません。
今回は 「すべてローカルGPUで完結させる」 ことを目指し、Xinferenceを採用します。
環境構築:Docker Compose#
DifyとXinferenceをDocker Composeを使ってセットアップします。まず、Difyのリポジトリをクローンします
# 例:Gitリポジトリをクローン
git clone https://github.com/langgenius/dify.git
cd dify/docker
次に、docker-compose.yml ファイルにXinferenceのサービス定義を追加します。
# docker-compose.yml の services: 以下に追記
....
# 以下を追加
xinference:
image: xprobe/xinference:latest
container_name: xinference # コンテナ名を指定すると管理しやすい
ports:
- "9997:9997"
# モデルデータなどを永続化したい場合はボリュームを設定
# volumes:
# - xinference_data:/root/.xinference
command: xinference-local --host 0.0.0.0 --port 9997
deploy: # GPUを利用する場合
resources:
reservations:
devices:
- driver: nvidia
count: all # 利用するGPU数を指定 (例: 1)
capabilities: [gpu]
restart: always # 常に再起動する設定
# 必要に応じてvolumesセクションを末尾に追加
# volumes:
# xinference_data:
注意点:
- GPUを利用せずCPUを利用する場合は
deploy:セクションは不要です。 count: allはすべての利用可能なGPUを割り当てます。特定のGPUを指定したい場合はdevice_ids: ['0']のようにします。- Xinferenceがダウンロードするモデルファイルはサイズが大きくなることがあります(モデルによっては合計で数十GB以上)。ディスクの空き容量に注意してください。実際に弊社の環境だと30GBほど取られました
docker-compose.yml を編集したら、.env.example ファイルを .env にコピーし、必要に応じて設定を編集します(通常はデフォルトのままでも動作します)。
cp .env.example .env
準備ができたら、Docker Composeを起動します。
docker compose up
初回はイメージのダウンロードに時間がかかります。
上記の流れについては公式に記載されています。
Xinference でモデルをダウンロード#
Dockerコンテナが正常に起動したら、まずはxinferenceの設定をします。
Webブラウザで http://localhost:9997 にアクセスするとXinferenceの管理UIが表示されます。ここからRAGに必要な3種類のモデル(LLM, Embedding, Re-ranking)をダウンロードします。
1. LLM のダウンロード#
http://localhost:9997/ui/#/launch_model/llm にアクセスしてみましょう。
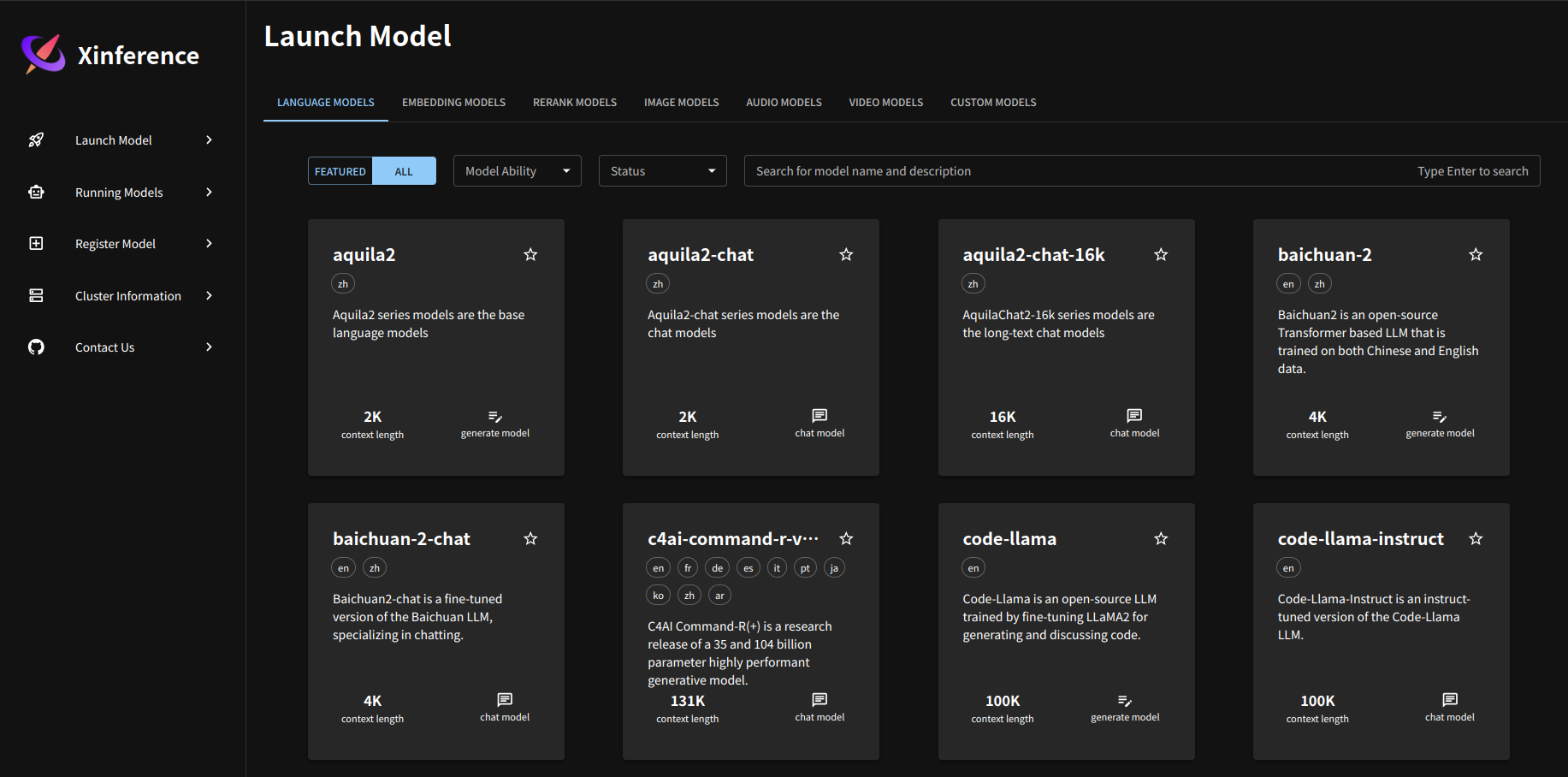
上記のように様々なLLMモデルを表示されています。今回はqwen2.5 instructを使ってみます。(モデルは正直なんでも良いのですが、日本語に対応しているものを選びました。)。検索窓から絞り込むことが可能です。
今回使用した変数 クリックすると、色々と入れる画面があるのですが、指定した値は次のとおりです。model_engine: llama.cpp, model_format: ggufv2, model_size: 1_5, quantization: q8_0 (あとはデフォルト)
Tips: モデル名の横に EN, ZH と書かれていても、多言語対応モデルであれば日本語も扱える場合があります(Qwen2シリーズなど)。
注意: 新しすぎるモデルは、Xinferenceがまだ対応しておらずエラーになることがあります。安定性を重視する場合は、実績のあるモデルを選ぶのが無難です。例えば、2025年3月にリリースしたGemma3など2025年4月に試しましたが、新しすぎてエラーが出ました。
モデルを選択し、「Launch」ボタンをクリックします。ダウンロードと起動が始まります。(20分程かかりました)
2. Embedding モデルのダウンロード#
次に http://localhost:9997/ui/#/launch_model/embedding をクリックしてください。Embeddingモデルをダウンロードします。今回は多言語対応で評価の高い bge-m3 を選択し、特にそのままでLaunchをクリックします。
3. Re-ranking モデルのダウンロード#
次にhttp://localhost:9997/ui/#/launch_model/rerank にアクセスします。
モデルは jina-reranker-v2 を選択してみます。有名な bge-reranker-v2-m3 など、他のモデルを試してみるのも良いでしょう。選択したらLaunchします。
これでXinference側でLLM、Embedding、Re-rankingの各モデルが利用可能な状態になりました。 下記のURLで設定が出来ているかどうか確認できます。
http://localhost:9997/ui/#/running_models/LLM http://localhost:9997/ui/#/running_models/embedding http://localhost:9997/ui/#/running_models/rerank
インストールが問題なければ、それぞれのモデルがリストされています。
Dify 側の設定#
次に、Dify側でXinferenceのモデルを使えるように設定し、ナレッジベースを作成してアプリケーションと連携させます。
Webブラウザで http://localhost:80 (docker-compose.yml でポートを変更していなければ)にアクセスし、Difyにログインします(初回アクセス時は管理者アカウントを作成)。
1. モデルプロバイダーの設定#
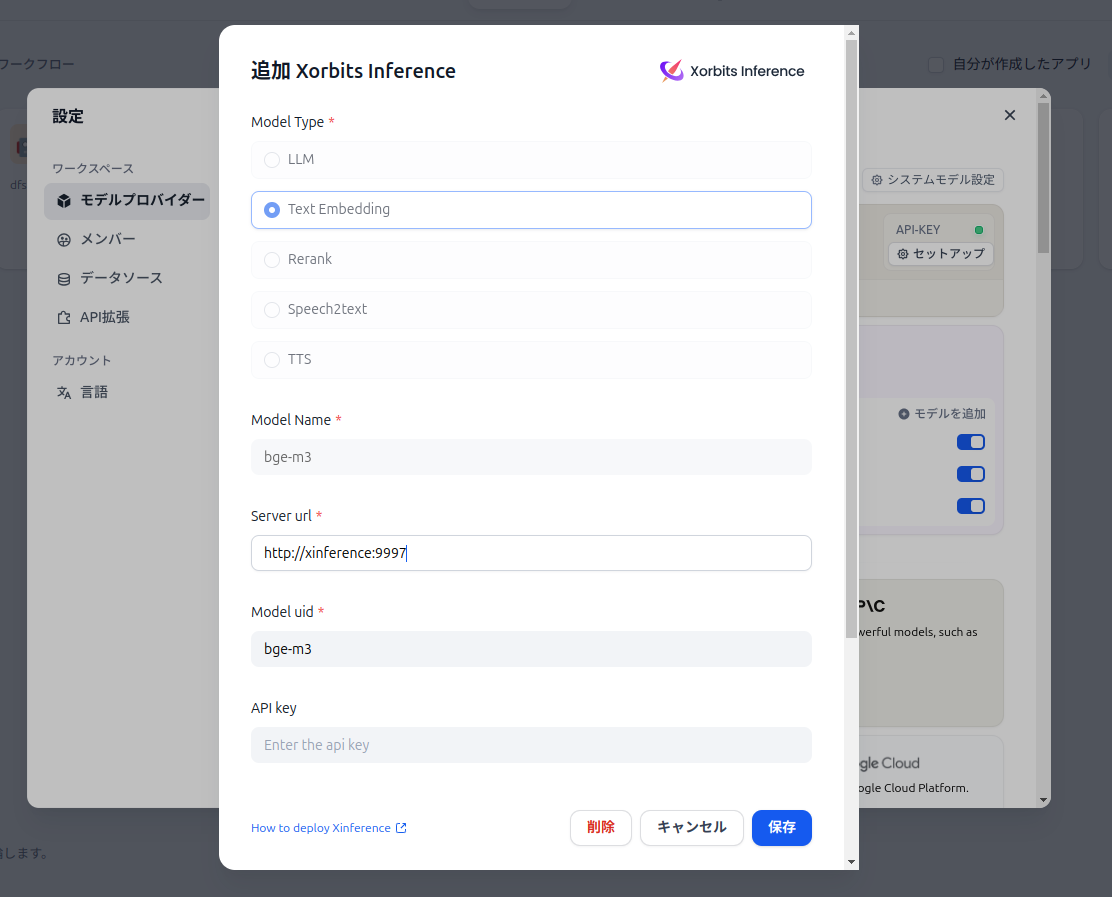
画面右上のアカウント名 > 「設定」> 「モデルプロバイダー」を選択します。リストから「Xinference」を見つけて「追加」ボタンをクリックします。
- サーバーURL: Xinferenceが動作しているURLを入力します。Docker Composeで連携している場合、Difyコンテナから見たXinferenceコンテナのサービス名を使います。(例:
http://xinference:9997)。もしDockerホストのIPアドレスを使う場合はhttp://<DockerホストのIP>:9997のようになります。 - モデルの選択: 「モデルタイプを選択」のドロップダウンから、先ほどXinferenceで起動したLLM、Embedding、Re-rankingの各モデルをそれぞれ選択し、追加していきます。
設定が完了したら「保存」します。
2. ナレッジの作成(知識DBの作成)#
左メニューの「ナレッジ」をクリックし、「ナレッジを作成」ボタンから新しいナレッジベースを作成します(例:「社内ドキュメント」など)。
作成したナレッジベースを開き、「ドキュメントを追加」から、知識源としたいファイル(PDF, TXT, Markdown, DOCXなど)をアップロードします。
今回弊社では「諺」をいれました。最初、知識データベースで諺の質問をし、恐らく1.5B程度だと無茶苦茶な回答が返ってきます。これで、どの程度精度がアップしたのか後ほど確認しましょう。
アップロード後、Difyが自動的にドキュメントをチャンク(断片)に分割し、Embeddingモデルを使ってベクトル化する処理(インデックス作成)を行います。これには少し時間がかかる場合があります。「ドキュメント」タブで処理状況を確認できます。
さて、ナレッジを作る際には、xinference のEmbeddingモデルを指定します。下の画像のように今回インストールしたモデルを参照していきます。
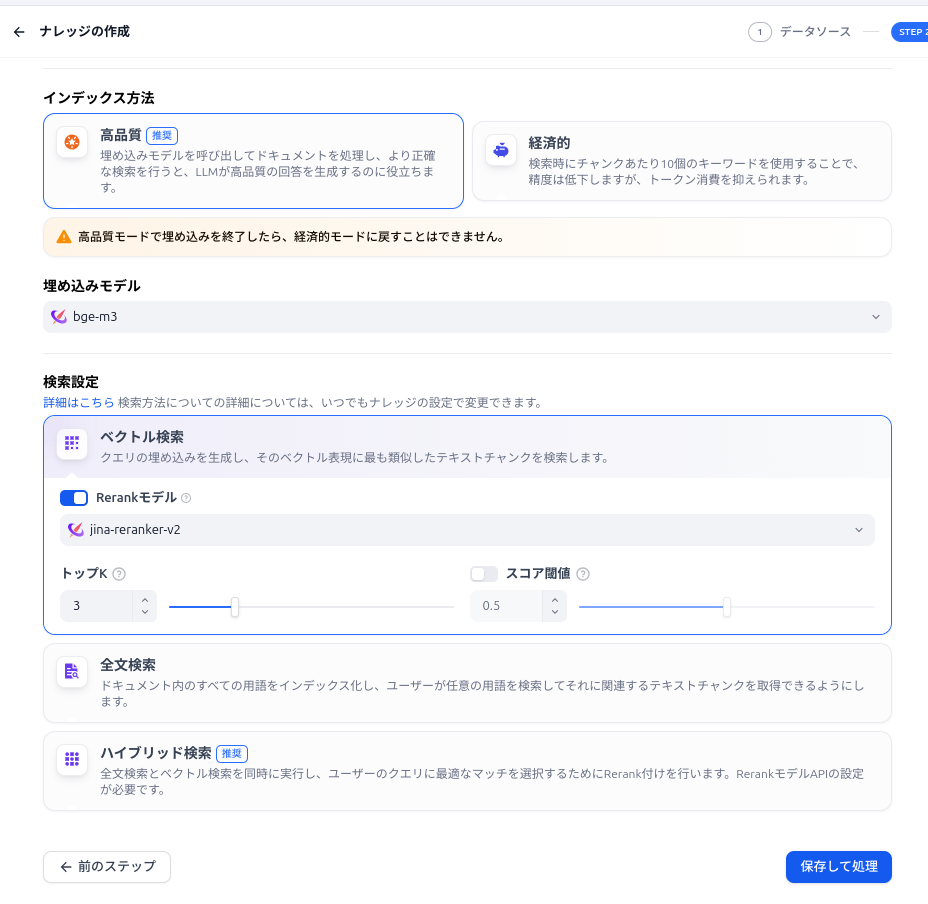
Embeddingだけでなくre-rankingモデルも指定しておいてください。
3. アプリケーションの作成と連携#
左メニューの「スタジオ」をクリックし、「アプリを作成する」の中の「最初から作成する」ボタンをクリックします。
チャットフローを作成しましょう。
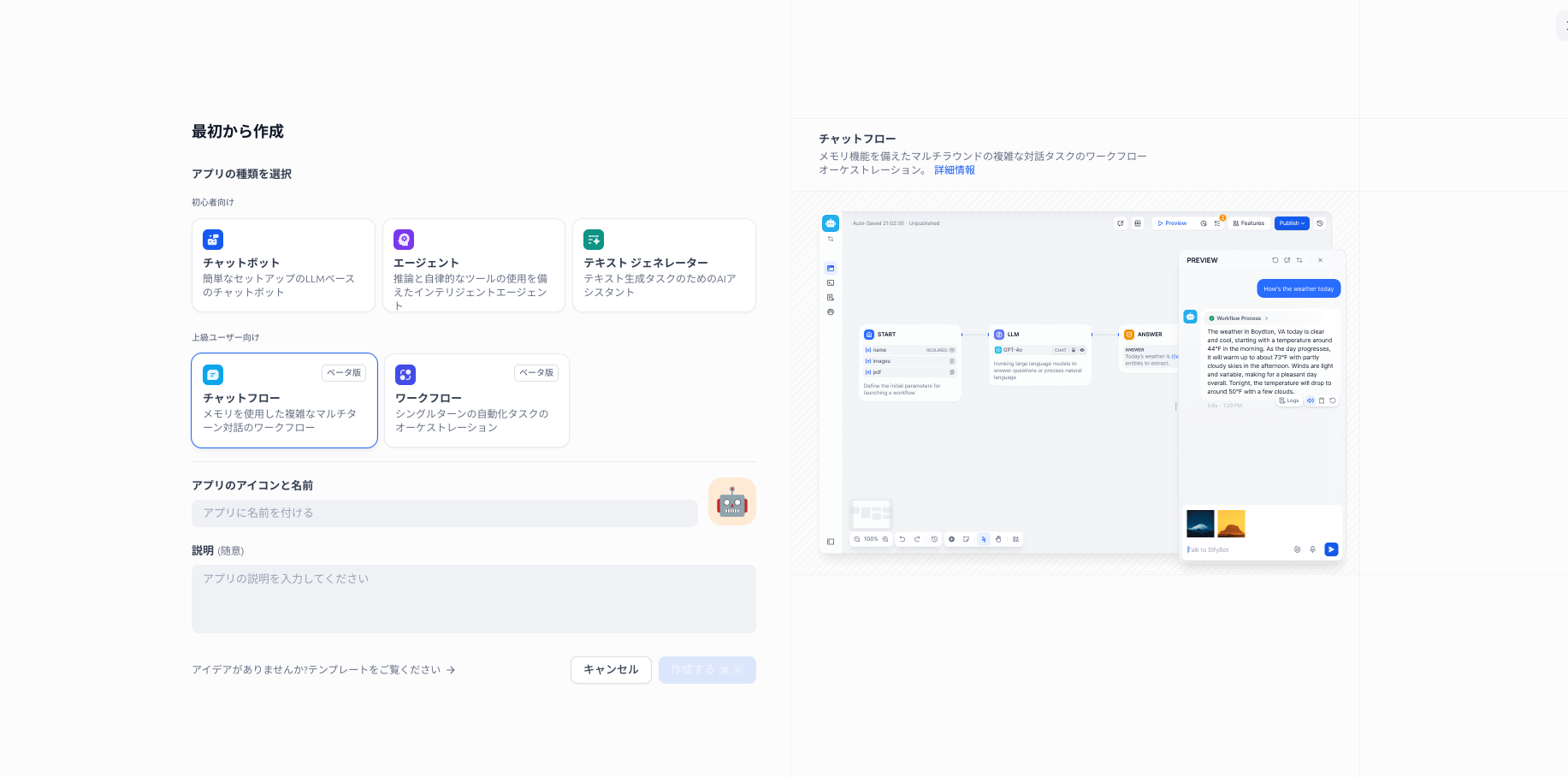
フロー画面が立ち上がったら、LLMの設定をします。モデルは今回ダウンロードした
qwen2.5-insturctをクリックします。(弊社の環境だとcohereもインストールしてしまっているので、色々出ていますが、今回のチュートリアルではxinferenceだけなはずです。)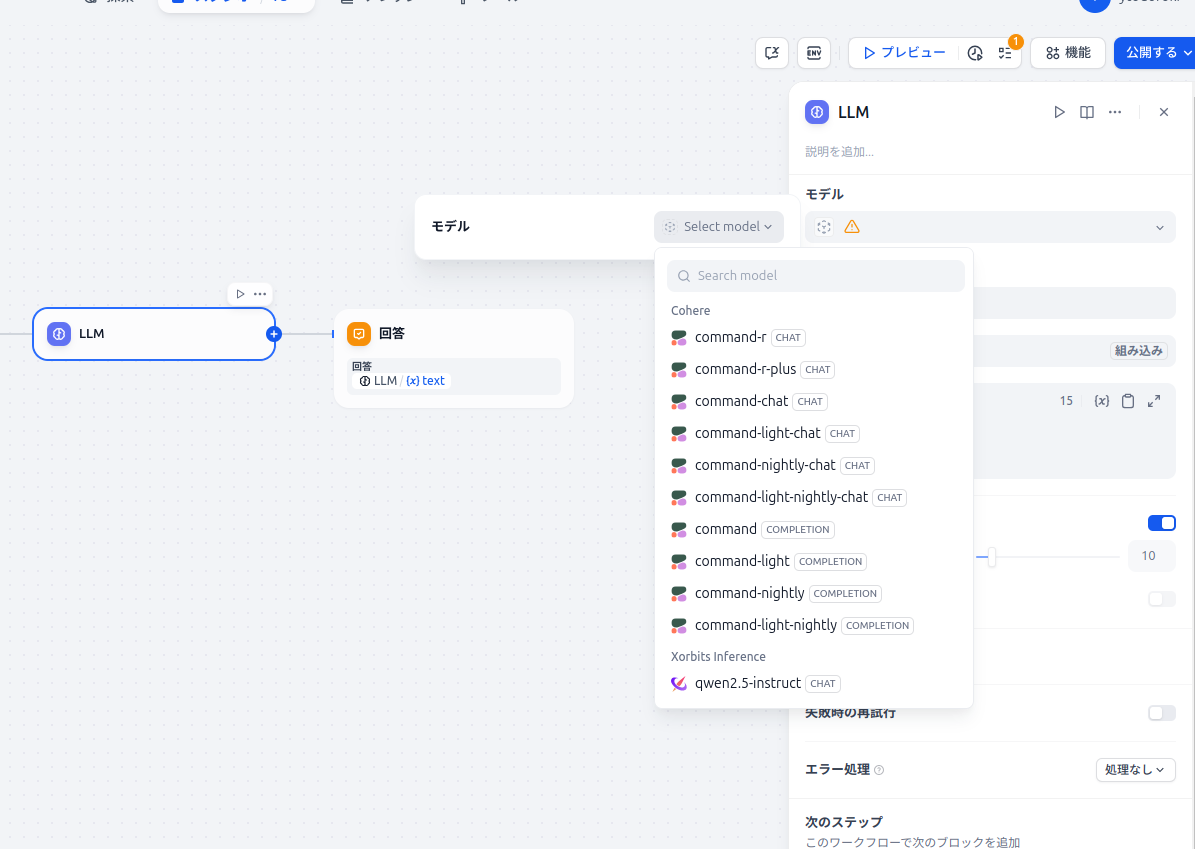
開始とLLMの間の線のプラスマークを押します。
知識取得をクリックしてください。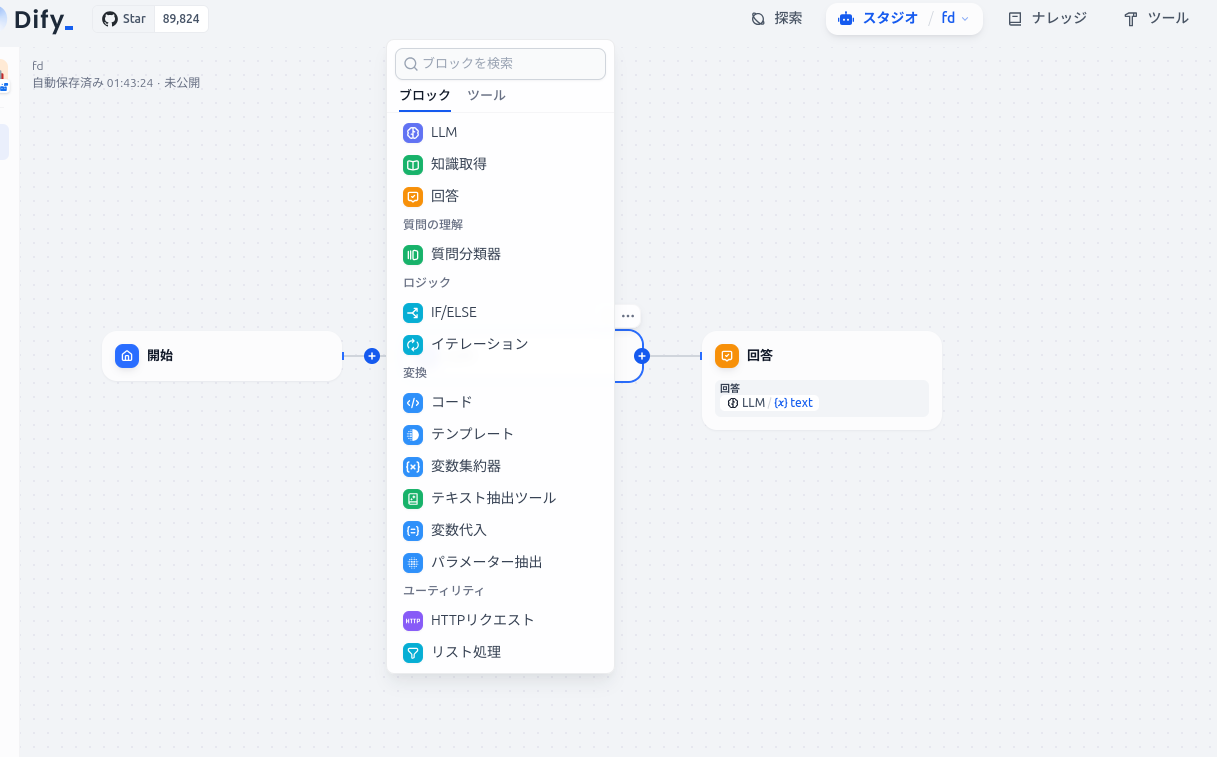
ここでRe-rankモデルを検索設定で指定します。
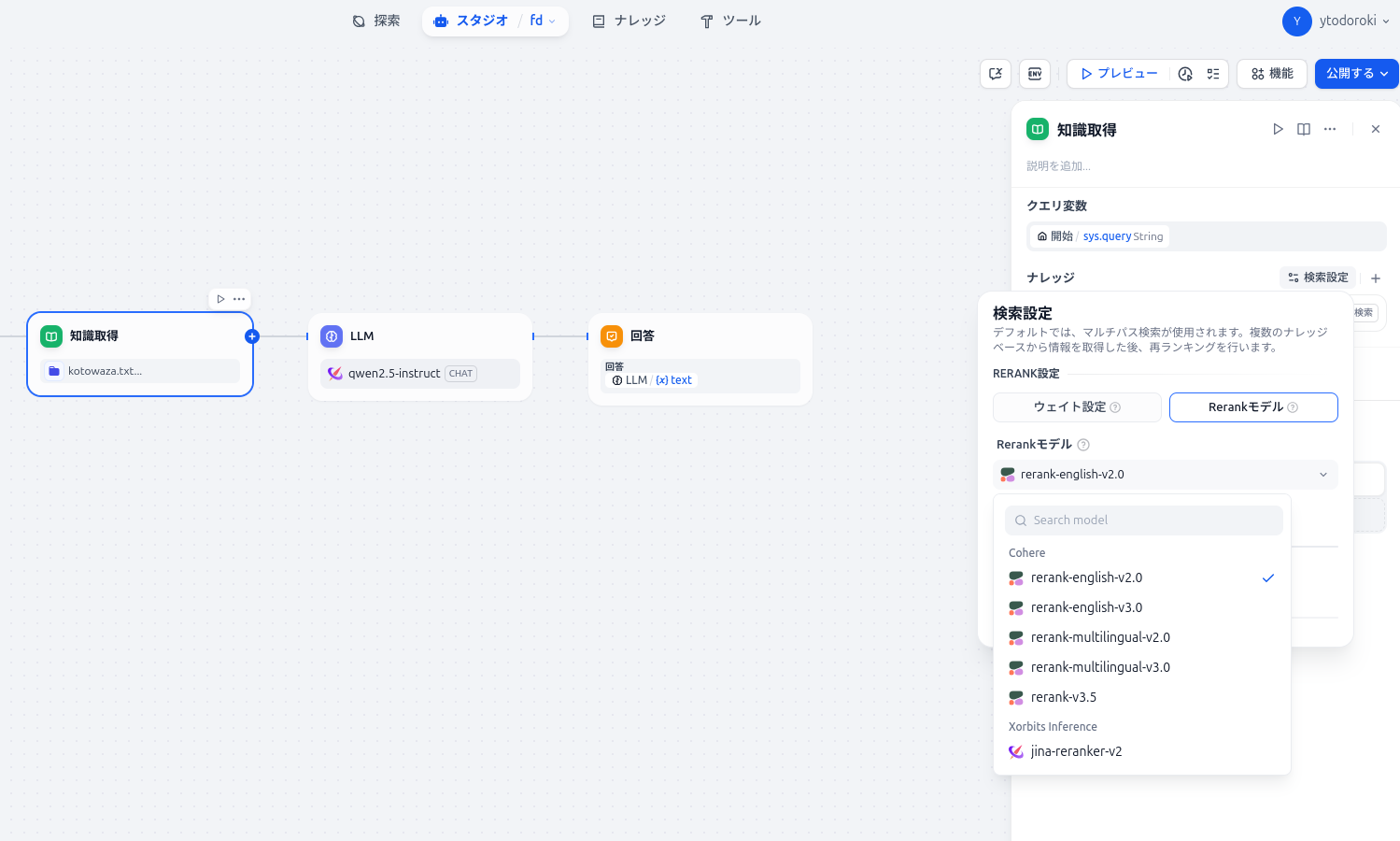
これだけです。一度右上のプレビューから問題ないかテストすることが出来ます。テストで問題なければそのまま公開となります。
動作確認#
画面右側のプレビューエリアや、「概要」タブの「アプリを実行」から、作成したチャットボットに質問を投げかけてみましょう。ナレッジベースに追加したドキュメントの内容に基づいて回答が生成されれば、RAGシステムが正しく機能しています。
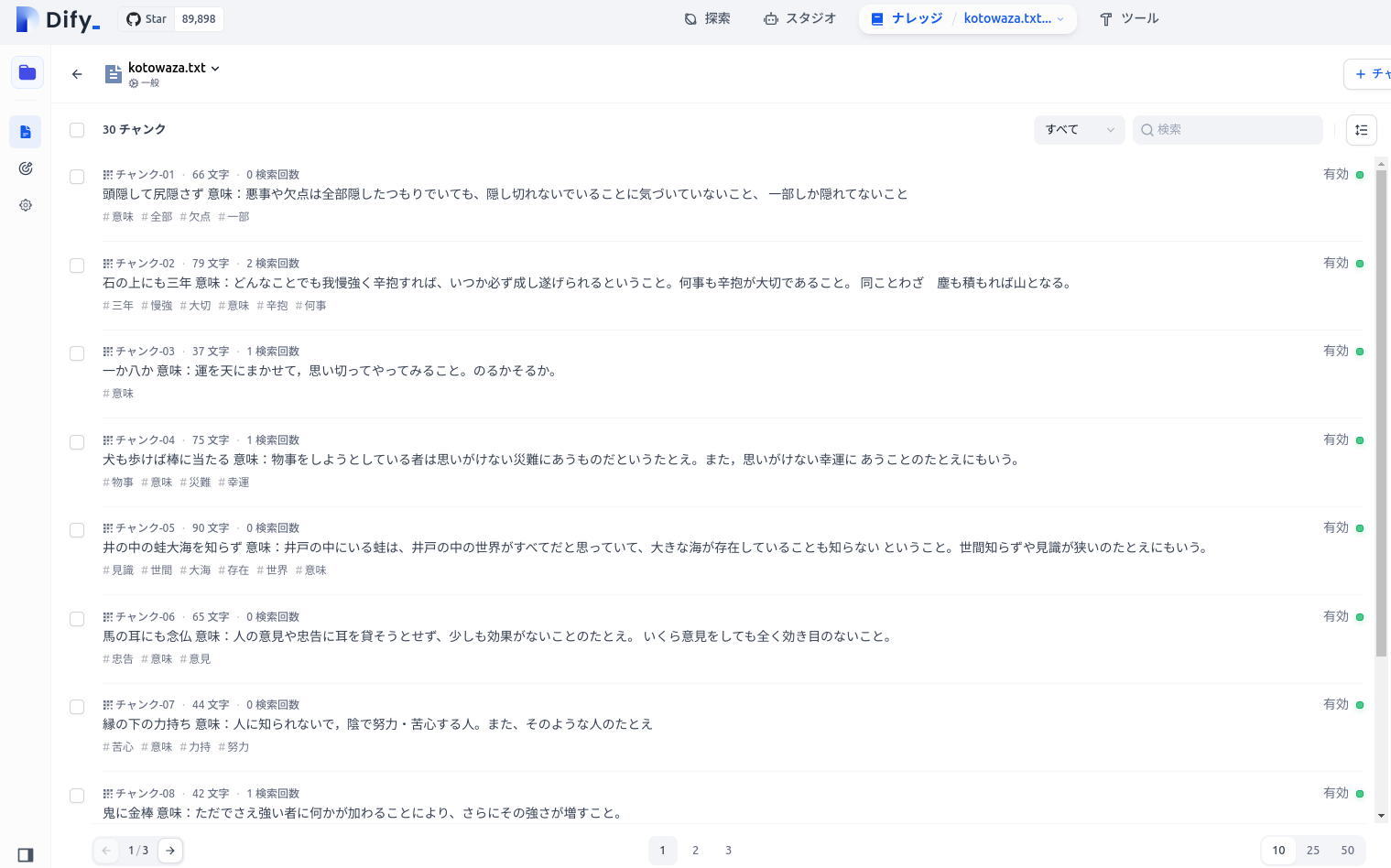
弊社の環境では、ことわざのリストを取得して読ませました。例えば犬も歩けば棒に当たる、石の上にも3年など、知識ベースなしでは無茶苦茶な回答をしてきましたが、知識ベースありだときちんとした回答が得られます。
Difyのナレッジのところをクリックし、アップロードしたファイルから、どの諺がヒットしたのかなども確認できます。
まとめ#
今回は、DifyとXinferenceを組み合わせることで、LLM、Embedding、Re-rankingのすべてをローカルGPU環境で動作させるRAGシステムを構築する手順を紹介しました。
これにより、機密性の高い情報を外部に出すことなく、独自の知識に基づいた高度なLLMアプリケーションを構築できます。
もちろん、モデルの選択やプロンプトの調整、チャンク戦略など、精度を高めるための工夫は様々ありますが、まずは第一歩としてローカルRAG環境を体験してみてください。

画像処理エンジニア。組み込みソフト出身。 株式会社モルフォにてR&D部門、主に機械学習業務に携わり、顔認識&顔検出のアルゴリズム開発に従事。国内特許数件、国際特許1件。 モルフォ社退社後、株式会社Dynaptico創業(CEO)。アメリカ人、スウェーデン人と3名とフードデリバリーサイトmaishoku.comを立ち上げる。社長業の他、開発業務においてバックグラウンド関連全般(Djangoを用いいたバックエンドサーバ&APIサーバーの作成、 リバースプロキシなどの負荷分散サーバ関連、OCRプログラムの作成、CISCOルータの管理, 、seleniumを用いたテストサーバーの構築、Androidアプリの開発等々)に携わる。 2019年DynapticoのCEOを辞職。 2020年2月にComputer Scienceに特化した株式会社OctOpt創業。 OSはUbuntu。Appleが苦手。Swiftのバージョンアップ対応とか死ぬほど嫌い。 Python/C++/C Twitter: @rocky_house シフト自動調整スケジュールサイトをVue.js+graphene djangoで構築. https://www.allshifter.com https://iamfax.com