Ollama WebUI入門:自宅GPUで動くChatGPT代替環境の作り方
はじめに#
ローカル環境でChatGPTを作る方法を説明します。まず大前提ですがGPUといわれるハードウェアが必要になります。
更にGPUがあればいいという話ではなく、最低でも8GB以上のメモリ(VRAMという)を積んだものを用意してください。また、NvidiaのGPUを前提に説明していこうと思います。
ローカルでChatGPTを使いたい理由はいくつかあると思います。例えば、
- データ漏洩を心配している
- プログラマー
- トークンを大量に消費するサービスを運営する必要がある
- オフラインでも利用したい
- RAGなどを使って、特定の環境に特化したLLMを作成したい
- 研究開発
などです。
そうした人のための参考記事と慣れば幸いです。
ollama とは#
ollamaは言語モデルを管理するためのツールで、いま数多あるLLMを利用するために、標準になっているツールです。
ユーザーは気になるLLMをollamaを通じてダウンロードしていきます。
ollamaがインストールできていれば、次のコマンドを打鍵するだけでモデルを試すことが出来ます。
# model のダウンロード
$ ollama pull gemma3:12b
# model を実行する
$ ollama run gemma3:12b
LLMモデル自体は、実に様々なGoogle, meta, alibaba, deepseekなど実に様々な会社から提供されており、ChatGPTに近い性能を持っています。
ollamaのインストール#
ollamaの環境を構築するにはdockerを使います。今次のようなdocker-compose.ymlを用意します。
services:
ollama:
image: ollama/ollama:0.6.1
container_name: ollama
ports:
- "11434:11434"
volumes:
- ollama_data:/root/.ollama
# GPUを使用する場合
deploy:
resources:
reservations:
devices:
- capabilities: [gpu]
あとはdocker compose upするだけです。
nvidia関連のdocker ツールをダウンロードする#
GPUがNVIDIAの場合は、そのためのツールをインストールする必要があります。(INTEL, AMD GPUの人も適時する必要があると思うのですが、申し訳ないのですが詳しいことはわかりません)
nvidia docker のインストールは公式を参考にします。
色々とややこしく書かれているので以下に端的にやることを切り出します。(上記のインストラクションを切り出しただけです)
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
# Configure NVIDIA Container Toolkit
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart docker
ollamaを動かしてみる#
docker compose upしている状態でコンテナに入ってみます。
docker compose exec ollama bash と打ちコンテナ内に入ります。
中には入れたら、Alibaba社が作ったLLM, qwen2.5-coder を実行してみます。8gbのGPUであればqwen2.5-coder:7bが動きます。VRAMを5GB程度消費していました。
root@8e46ff464088:/# ollama run qwen2.5-coder:7b
>>> フィボナッチ数列を書いて!
....
と、こんな感じで命令すれば、結果が出力されます。
色々なモデルをダウンロードしたい#
ollama.comにいくと、様々なモデルが有り、そこから自分の好きなモデルをダウンロード出来ます。
先に紹介したqwen2.5-coderは量子化に対応したライブラリもたくさんあり、それらもダウンロードできます。qwen2.5-coderの一覧を参考にして見てください。
gemma3などのLLMも量子化対応したmodel`を公開しています。GPUのメモリに余裕がない人は量子化対応版を使ってみましょう。
蛇足ですが、2025年3月末にGoogleのgemma3をリリースしました。日本語のLLMでコーディング以外の利用用途の場合は、gemma3がおすすめです。GPUの対応表は次のとおりです。
| パラメータ数 (B) | VRAM要件 (Text-to-Text) | VRAM要件 (Image-to-Text) | 推奨GPU |
|---|---|---|---|
| 1B | 2.3 GB | サポートなし | GTX 1650 4GB |
| 4B | 9.2 GB | 10.4 GB | RTX 3060 12GB |
| 12B | 27.6 GB | 31.2 GB | RTX 5090 32GB |
| 27B | 62.1 GB | 70.2 GB | RTX 4090 24GB (x3) |
ただ実際にgemma3: 4Bを使ってみたところ、VRAMは4GB程度しか使っていなかったため、上記よりは結構余裕があるのかなと感じています。
webuiを使ってみる#
今のままだと使い勝手が悪いので、webuiを利用します。
これは、ChatGPTのようなインターフェースを提供してくれるツールです。
一番最初に提示したdocker-compose.ymlを次のように編集します。
services:
ollama:
image: ollama/ollama:0.6.1
container_name: ollama
ports:
- "11434:11434"
volumes:
- ollama_data:/root/.ollama
restart: unless-stopped
# GPUを使用する場合
deploy:
resources:
reservations:
devices:
- capabilities: [gpu]
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
ports:
- "3000:8080"
volumes:
- open_webui_data:/app/backend/data
environment:
- OLLAMA_BASE_URL=http://ollama:11434
- ENABLE_WEBSOCKET_SUPPORT=false
# extra_hosts:
# - "host.docker.internal:host-gateway"
depends_on:
- ollama
restart: always
volumes:
ollama_data:
open_webui_data:
このコードは公式のdocker-compose.yamlを若干編集したものです。公式
変更箇所ですが、extra_hostsはホスト側のネットワークを使う設定なのですが、特に指定する必要性がないのでコメントアウトしています。
また、ENABLE_WEBSOCKET_SUPPORT=false にしていますが、これをしないとSyntaxError: Unexpected token 'd', "data: {"id"... is not valid JSON? というエラーが出てしまいました。この解決方法として、ここ を参考に追加しました。
さて、早速docker compose upをしてみます。
http://localhost:3000を叩けば、webui経由でChatGPTライクなインターフェイスが起動します。次のような形になります。
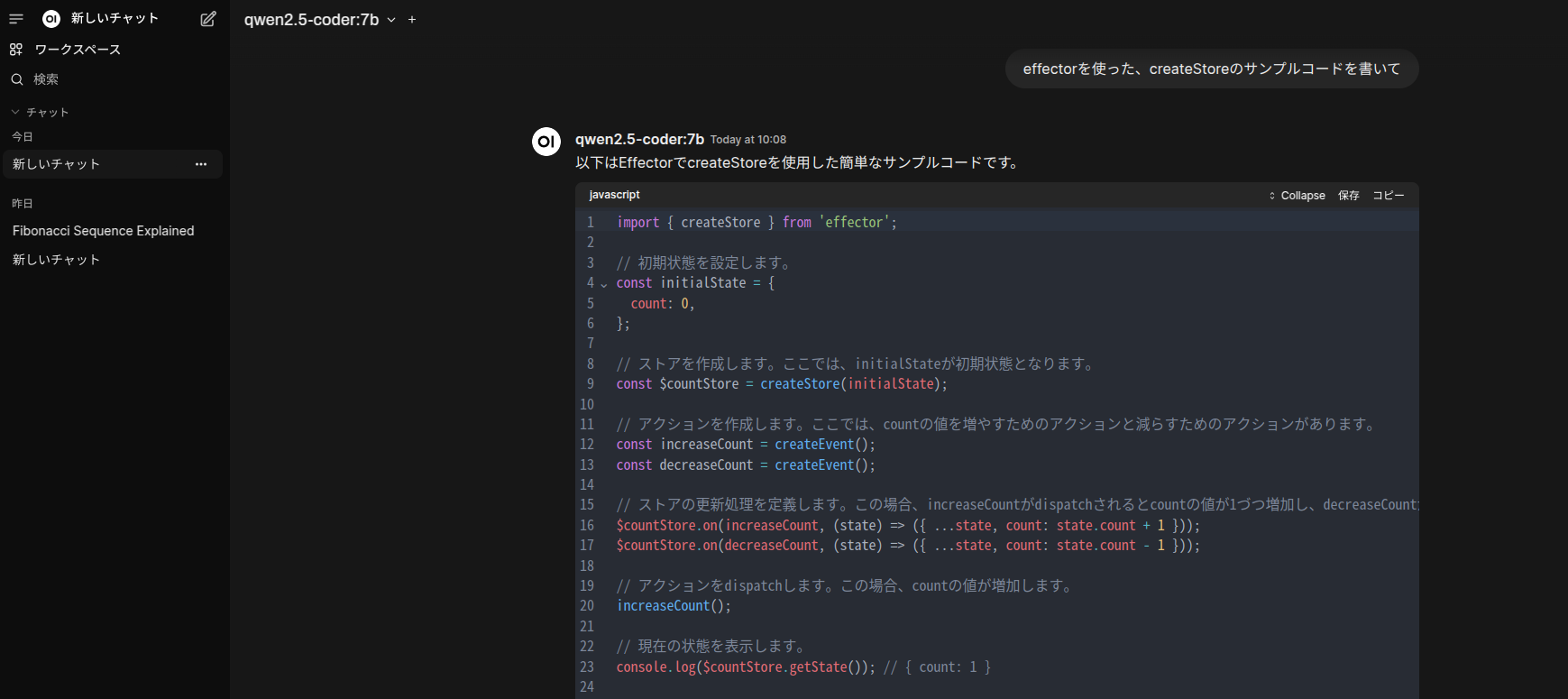
馴染み深いChatGPTを彷彿させるウィンドウで、質問もサクサク答えてくれます。
弊社の環境ではgtx1080ですが、問題なく答えてくれています。
まとめ#
ollamaとWebUIを使えば、自前のGPU環境で手軽にLLMを活用できます。
特に開発者向けのコーディング支援モデルから汎用モデルまで、自分の用途とGPUリソースに合わせた選択が必要ですが、ネットで色んな人が試しているので、そういう記事を参考に色々と試行錯誤してみてください。
次回はdifyを使ったやり方や、RAGをやって見る方法をご紹介していきたいと思います。

画像処理エンジニア。組み込みソフト出身。 株式会社モルフォにてR&D部門、主に機械学習業務に携わり、顔認識&顔検出のアルゴリズム開発に従事。国内特許数件、国際特許1件。 モルフォ社退社後、株式会社Dynaptico創業(CEO)。アメリカ人、スウェーデン人と3名とフードデリバリーサイトmaishoku.comを立ち上げる。社長業の他、開発業務においてバックグラウンド関連全般(Djangoを用いいたバックエンドサーバ&APIサーバーの作成、 リバースプロキシなどの負荷分散サーバ関連、OCRプログラムの作成、CISCOルータの管理, 、seleniumを用いたテストサーバーの構築、Androidアプリの開発等々)に携わる。 2019年DynapticoのCEOを辞職。 2020年2月にComputer Scienceに特化した株式会社OctOpt創業。 OSはUbuntu。Appleが苦手。Swiftのバージョンアップ対応とか死ぬほど嫌い。 Python/C++/C Twitter: @rocky_house シフト自動調整スケジュールサイトをVue.js+graphene djangoで構築. https://www.allshifter.com https://iamfax.com